![]()
Flow cytometry#
Here, you will
read a single
.fcsfile as anAnnDataand seed a versioned dataset with itappend a new data batch (a new
.fcsfile) to create a new version of the datasetlook at an overview of ingested files and cell markers
query the data and store analytical results as plots
Setup#
!lamin init --storage ./test-facs --schema bionty
Show code cell output
✅ saved: User(id='DzTjkKse', handle='testuser1', email='testuser1@lamin.ai', name='Test User1', updated_at=2023-09-29 14:47:29)
✅ saved: Storage(id='uyxQ7P2z', root='/home/runner/work/lamin-usecases/lamin-usecases/docs/test-facs', type='local', updated_at=2023-09-29 14:47:29, created_by_id='DzTjkKse')
💡 loaded instance: testuser1/test-facs
💡 did not register local instance on hub (if you want, call `lamin register`)
import lamindb as ln
import lnschema_bionty as lb
import readfcs
lb.settings.species = "human"
💡 loaded instance: testuser1/test-facs (lamindb 0.54.3)
ln.track()
💡 notebook imports: lamindb==0.54.3 lnschema_bionty==0.31.2 pytometry==0.1.4 readfcs==1.1.6 scanpy==1.9.5
💡 Transform(id='OWuTtS4SAponz8', name='Flow cytometry', short_name='facs', version='0', type=notebook, updated_at=2023-09-29 14:47:31, created_by_id='DzTjkKse')
💡 Run(id='XrTJbAKJspEWgiAhQCHj', run_at=2023-09-29 14:47:31, transform_id='OWuTtS4SAponz8', created_by_id='DzTjkKse')
Ingest a first file#
Access  #
#
We start with a flow cytometry file from Alpert et al., Nat. Med. (2019).
Calling the following function downloads the file and pre-populates a few relevant registries:
ln.dev.datasets.file_fcs_alpert19(populate_registries=True)
PosixPath('Alpert19.fcs')
We use readfcs to read the raw fcs file into memory and create an AnnData object:
adata = readfcs.read("Alpert19.fcs")
adata
AnnData object with n_obs × n_vars = 166537 × 40
var: 'n', 'channel', 'marker', '$PnB', '$PnE', '$PnR'
uns: 'meta'
Transform: normalize  #
#
In this use case, we’d like to ingest & store curated data, and hence, we split signal and normalize using the pytometry package.
import pytometry as pm
pm.pp.split_signal(adata, var_key="channel")
'area' is not in adata.var['signal_type']. Return all.
pm.tl.normalize_arcsinh(adata, cofactor=150)
Validate: cell markers  #
#
First, we validate features in .var using CellMarker:
validated = lb.CellMarker.validate(adata.var.index)
❗ 13 terms (32.50%) are not validated for name: Time, Cell_length, Dead, (Ba138)Dd, Bead, CD19, CD4, IgD, CD11b, CD14, CCR6, CCR7, PD-1
We see that many features aren’t validated because they’re not standardized.
Hence, let’s standardize feature names & validate again:
adata.var.index = lb.CellMarker.standardize(adata.var.index)
validated = lb.CellMarker.validate(adata.var.index)
❗ 5 terms (12.50%) are not validated for name: Time, Cell_length, Dead, (Ba138)Dd, Bead
The remaining non-validated features don’t appear to be cell markers but rather metadata features.
Let’s move them into adata.obs:
adata.obs = adata[:, ~validated].to_df()
adata = adata[:, validated].copy()
Now we have a clean panel of 35 validated cell markers:
validated = lb.CellMarker.validate(adata.var.index)
assert all(validated) # all markers are validated
Register: metadata  #
#
Next, let’s register the metadata features we moved to .obs.
For this, we create one feature record for each column in the .obs dataframe:
features = ln.Feature.from_df(adata.obs)
ln.save(features)
We use the Experimental Factor Ontology through Bionty to create a “FACS” label for the dataset:
lb.ExperimentalFactor.bionty().search("FACS").head(2) # search the public ontology
| ontology_id | definition | synonyms | parents | molecule | instrument | measurement | __ratio__ | |
|---|---|---|---|---|---|---|---|---|
| name | ||||||||
| fluorescence-activated cell sorting | EFO:0009108 | A Flow Cytometry Assay That Provides A Method ... | FACS|FAC sorting | [] | None | None | None | 100.0 |
| BALB/c | EFO:0000602 | Balb/C Is A Mouse Strain Of Albion Mice. | BALB/cJ|C|BALBc | [] | None | None | None | 90.0 |
# import the record from the public ontology and save it to the registry
lb.ExperimentalFactor.from_bionty(ontology_id="EFO:0009108").save()
# show the content of the registry
lb.ExperimentalFactor.filter().df()
| name | ontology_id | abbr | synonyms | description | molecule | instrument | measurement | bionty_source_id | updated_at | created_by_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||
| lh5Cxy8w | fluorescence-activated cell sorting | EFO:0009108 | None | FACS|FAC sorting | A Flow Cytometry Assay That Provides A Method ... | None | None | None | ZWwI | 2023-09-29 14:47:39 | DzTjkKse |
Register: data & annotate with metadata #
modalities = ln.Modality.lookup()
features = ln.Feature.lookup()
efs = lb.ExperimentalFactor.lookup()
species = lb.Species.lookup()
file = ln.File.from_anndata(
adata, description="Alpert19", field=lb.CellMarker.name, modality=modalities.protein
)
... storing '$PnE' as categorical
... storing '$PnR' as categorical
file.save()
Inspect the registered file#
Inspect features on a high level:
file.features
Features:
var: FeatureSet(id='MWRLB8OdxwlLfTuql5cA', n=35, type='number', registry='bionty.CellMarker', hash='ldY9_GmptHLCcT7Nrpgo', updated_at=2023-09-29 14:47:39, modality_id='vawwFF7K', created_by_id='DzTjkKse')
'CD127', 'Cd14', 'CD85j', 'CD11B', 'CD3', 'Igd', 'CD161', 'CXCR5', 'Ccr7', 'CD86', 'CD20', 'DNA2', 'Cd19', 'DNA1', 'CD16', 'CD24', 'CD28', 'CD45RA', 'CD33', 'ICOS', ...
obs: FeatureSet(id='bgrsk8EgBjPPo6tMU2aU', n=5, registry='core.Feature', hash='GhkLyME1vFEwCn68aptp', updated_at=2023-09-29 14:47:39, modality_id='TD3Mlzb5', created_by_id='DzTjkKse')
Time (number)
Cell_length (number)
Bead (number)
(Ba138)Dd (number)
Dead (number)
Inspect low-level features in .var:
file.features["var"].df().head()
| name | synonyms | gene_symbol | ncbi_gene_id | uniprotkb_id | species_id | bionty_source_id | updated_at | created_by_id | |
|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||
| hVNEgxlcDV10 | CD127 | IL7R | 3575 | P16871 | uHJU | qmjJ | 2023-09-29 14:47:34 | DzTjkKse | |
| roEbL8zuLC5k | Cd14 | CD14 | 4695 | O43678 | uHJU | qmjJ | 2023-09-29 14:47:34 | DzTjkKse | |
| lRZYuH929QDw | CD85j | None | None | None | uHJU | qmjJ | 2023-09-29 14:47:34 | DzTjkKse | |
| N2F6Qv9CxJch | CD11B | ITGAM | 3684 | P11215 | uHJU | qmjJ | 2023-09-29 14:47:34 | DzTjkKse | |
| a4hvNp34IYP0 | CD3 | None | None | None | uHJU | qmjJ | 2023-09-29 14:47:34 | DzTjkKse |
Use auto-complete for marker names:
markers = file.features["var"].lookup()
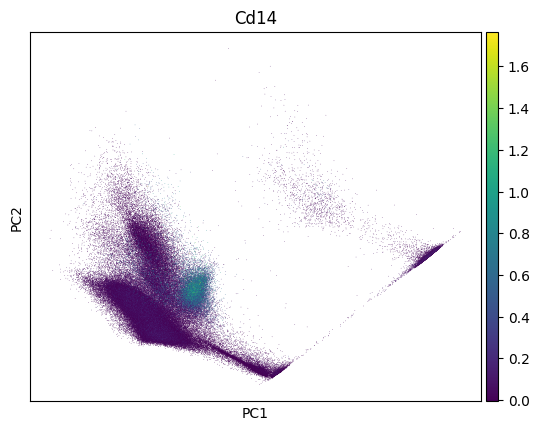
import scanpy as sc
sc.pp.pca(adata)
sc.pl.pca(adata, color=markers.cd14.name)
file.view_flow()

Create a dataset from the file#
dataset = ln.Dataset(file, name="My versioned FACS dataset", version="1")
dataset
Dataset(id='WmQQuZQyOo5E4NkwzF1r', name='My versioned FACS dataset', version='1', hash='Piw2n0vdnoNoAV7ZxgsW-g', transform_id='OWuTtS4SAponz8', run_id='XrTJbAKJspEWgiAhQCHj', file_id='WmQQuZQyOo5E4NkwzF1r', created_by_id='DzTjkKse')
Let’s inspect the features measured in this dataset which were inherited from the file:
dataset.features
Features:
var: FeatureSet(id='MWRLB8OdxwlLfTuql5cA', n=35, type='number', registry='bionty.CellMarker', hash='ldY9_GmptHLCcT7Nrpgo', updated_at=2023-09-29 14:47:39, modality_id='vawwFF7K', created_by_id='DzTjkKse')
'CD127', 'Cd14', 'CD85j', 'CD11B', 'CD3', 'Igd', 'CD161', 'CXCR5', 'Ccr7', 'CD86', 'CD20', 'DNA2', 'Cd19', 'DNA1', 'CD16', 'CD24', 'CD28', 'CD45RA', 'CD33', 'ICOS', ...
obs: FeatureSet(id='bgrsk8EgBjPPo6tMU2aU', n=5, registry='core.Feature', hash='GhkLyME1vFEwCn68aptp', updated_at=2023-09-29 14:47:39, modality_id='TD3Mlzb5', created_by_id='DzTjkKse')
Time (number)
Cell_length (number)
Bead (number)
(Ba138)Dd (number)
Dead (number)
This looks all good, hence, let’s save it:
dataset.save()
Annotate by linking FACS & species labels:
dataset.labels.add(efs.fluorescence_activated_cell_sorting, features.assay)
dataset.labels.add(species.human, features.species)
dataset.view_flow()
